AMD Ryzen AI 300 Series processors get higher overall results sin Llama.cpp-based applications such as LM Studio
AMD has showcased some interesting results in terms of its leading Ryzen AI 300 series processors for the laptop market outperforming competitor offerings in popular LLM applications.
One of them is LM Studio which is an offline-based tool and framework that lets users load in pre-trained LLM models and run them directly on the machine while relying mostly on CPU acceleration via AVX2 instructions with optional GPU support.
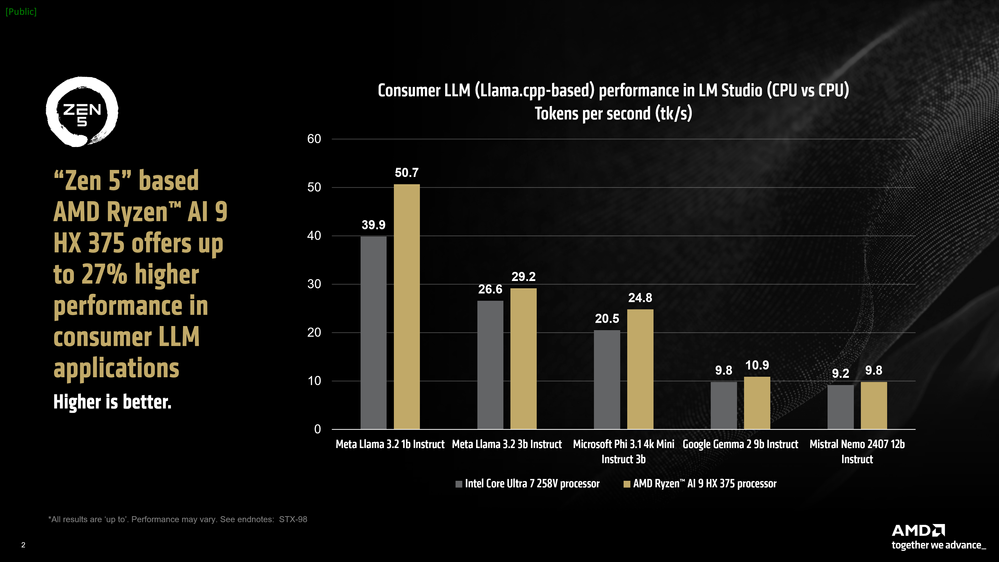
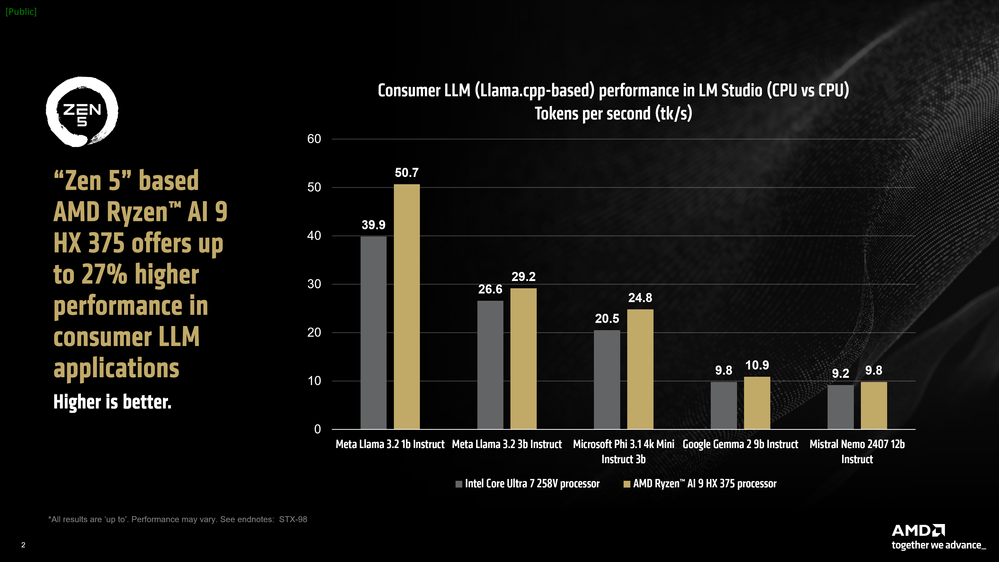
By comparing two similar systems running on different hardware, one can see that despite the Intel-based laptop having faster RAM (8533 MT/s) compared to the AMD system (7500 MT/s), Team Red still came out ahead with up to 27% faster performance in tokens per second (tk/s), a key metric representing the model’s output speed in words per second.
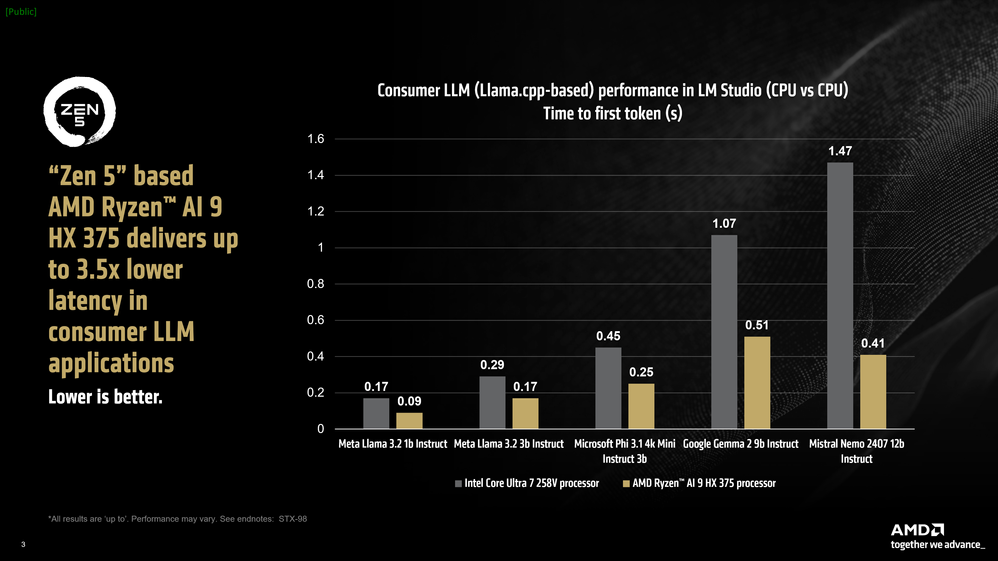
Particularly, the Ryzen AI 9 HX 375 processor reaches a rate of 50.7 tokens per second when running Meta Llama 3.2 1b Instruct at 4-bit quantization. Additionally, in terms of "time to first token", the chip managed to be up to 3.5x faster.
AMD also carefully designed its accelerators for specific purposes to achieve maximum efficiency. Take the XDNA 2-based NPUs for example, these are created for energy-efficient tasks, while the iGPU often handles on-demand AI processes.
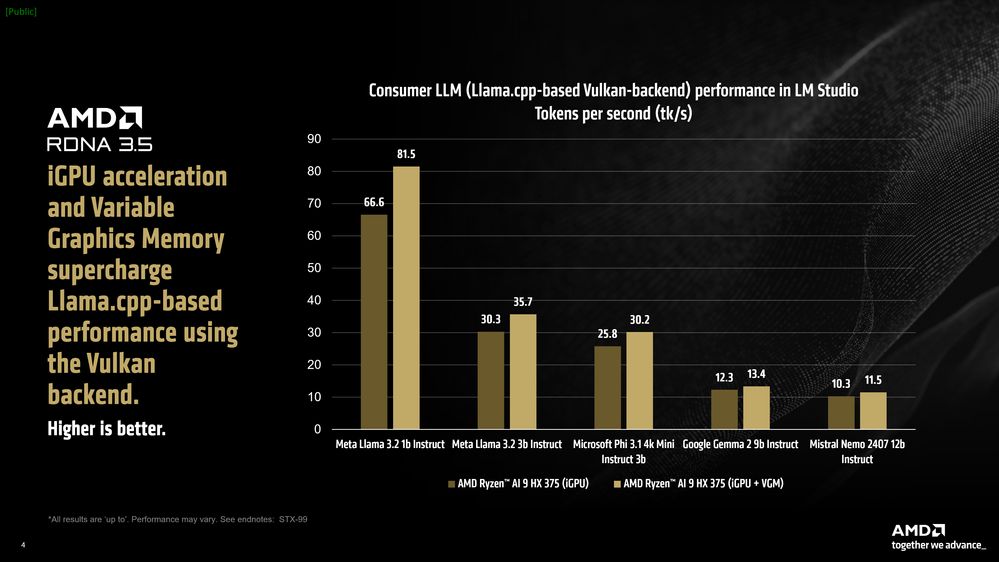
LM Studio incorporates a llama.cpp port that uses the vendor-neutral Vulkan API for GPU acceleration. Activating GPU offload in LM Studio enhanced performance by an average of 31% for Meta Llama 3.2 1b Instruct compared to CPU-only mode. Models with higher bandwidth demands, like Mistral Nemo 2407 12b Instruct, achieved a modest 5.1% average improvement.
Thanks to the Ryzen AI 300 series processors enabling Variable Graphics Memory (VGM) feature which allows the iGPU’s 512 MB dedicated memory allocation to expand up to 75% of available system RAM, a 16GB VGM test yielded an additional 22% increase in Meta Llama 3.2 1b Instruct performance, culminating in a total uplift of 60%.
For a fair analysis, AMD’s iGPU performance was compared to Intel’s AI Playground application, which utilizes models like Mistral 7b Instruct v0.3 and Microsoft Phi 3.1 Mini Instruct. Using similar quantization, AMD’s Ryzen™ AI 9 HX 375 processor proved 8.7% faster in Phi 3.1 and 13% faster in Mistral 7b Instruct 0.3.
If you wish to try out LM Studio yourself, you can click here.